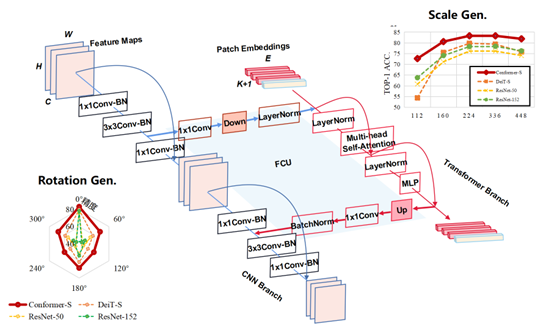
核心技术 代表性技术成果如下: 视觉大模型 提出局部与全局特征耦合的Conformer、HiViT、iTPN等新型表征结构,保证特征空间完备性与紧致性,为表示模型泛化提供新范式。基础模型在ImageNet1K和21K达84.1Top-1 精度超过同期2021-ICCV最佳论文Swin-Transformer。结合鹏城国家实验室云脑II平台训练的10亿参数表征模型ImageNet1k识别精度89.5%,达到同期国际先进 水平,支撑系列下游应用,如:显著提升了工业缺陷检测的精度10+%、交通标志分类(BelgiumTS)实际环境提升5.1%准确率,达到98.0%。 高精度工业缺陷检测技术 基于实验室研制的通用视觉基础模型架构,将现有Transformer的设计简化为层次化的特征嵌入,并移除滑动窗口注意力机制, 实现同等精度下训练效率显著提升的高效分层视觉模型(HiViT)。提出整体预训练的Transformer金字塔网络(iTPN), 首次尝试将层次化Transformer主干网和金字塔网络视为一个整体进行预训练,显著提升视觉表征的泛化能力。 研制了大模型模型适配方法,将通用视觉基础模型针对半导体晶圆/光伏缺陷的少样本场景进行高精度适配。 联合相关企业,形成了高精度工业缺陷检测技术。 多模态交互式具身智能系统 类脑世界模型指代仿照人类认知系统构建统一的视觉、语言交互及执行模块组合。本项目以语言与视觉大模型为“脑”,以视觉系统为“眼”、 以机器人系统为“手”,通过统一语义嵌入、提示学习与交互强化形成“知行合一”的类脑深度学习模型。模型包含实例级字典学习的视觉大模型模块、 语言引导的交互式视觉实例关系提取与开放环境下的语言引导机器感知模块。在视觉模型部分,通过分层结构、块级自监督学习、 实例级自监督学习形成从底层表征到语义表征的分层映射关系。在语言引导的交互式视觉感知方面,通过多模态嵌入建立语言与视觉表征关联。 通过机器人平台构建了具身智能系统原型。 X光违禁品检查软件 中国科学院大学共同承担了北京市科学技术委员会重点培育项目《基于弱监督深度学习的安全监测大数据平台研发及示范》,编号:Z161100001616005, 后续又与清华大学联合承担了北京市科学技术委员会重点培育项目《视觉目标自主学习技术与应用验证》,编号:Z181100008918014,进行了产学研深度融合。 课题研究成果在本公司的智慧机场、智慧物流等X光安全检查系统中得到应用。鉴于课题研究方法的弱监督、分层传播等优良特性,显著增加了安全检查系统的可 迁移性与整体部署效率,节约时间成本60%以上,显著提升了产品竞争力。 高精度遥感图像目标感知软件 基于课题组所研发的视觉大模型及高精度目标感知算法,开发了跨场景自主学习遥感目标识别系统,实现了复杂的遥感场景下大感受场 与局部感受场耦合的新型特征表示技术,完成了面向天基遥感目标检测的视觉大模型;通过复杂的遥感目标的语义依赖与局部精细表征 有效融合,实现高效准确的天基遥感场景的目标检测系统。